목표
1. 크롤링을 통해 네이버 금융주가 주가 가져오기
2. 머신러닝알고리즘을 적용해 주가 예측 모델 만들기
3. 성능 좋은 모델을 만들기
3-2. 딥러닝을 통한 예측
시계열 데이터에서 사용하는 순차 신경망(RNN) 을 이용한 예측. RNN부터 학습하고 와야겠다~
1. 데이터 가져오기
import pandas as pd
from sklearn.model_selection import train_test_split
import numpy as np
from tensorflow import keras
df = pd.read_excel('samsung.xlsx')
print(df)
2. 필요한 데이터 필드 가져오기 (문제지와 정답지 만들기)
dfx = df[['종가','시가','고가','저가','거래량']]
dfy = df['종가']아직은 데이터 프레임 형식으로 되어 있으므로 이를 분석을 위해 list 형태로 바꾸어준다.
x = dfx.values.tolist()
y = dfy.values.tolist()
x
y
이제 까지 실제 주식데이터 예측률은 60~70% 등이 최대라한다. 외부적 요인과 갑작스런 이슈 때문이다. 딥러닝을 사용하면 기존 한순간, 한시점을 학습하던 것을 일정기간 단위로 연속적으로 컴퓨터가 참고할수 있는 데이터를 주면 좋다고 한다.
먼저 데이터 표준화(스케일링)을 하자
data_x = []
data_y = []
window = 10
mean = np.mean(x, axis=0)
std = np.std(x, axis=0)
x = (x - mean)/std
x
데이터를 10개 단위로 경향성을 주어 RNN 학습을 시킨다.
data_x = []
data_y = []
window = 10
mean = np.mean(x, axis=0)
std = np.std(x, axis=0)
x = (x - mean)/std
for i in range(len(y)-window):
if y[i+window-1] < y[i+window]:
data_y.append(1)
else:
data_y.append(0)
data_x.append(x[i:i+window]) #0 ~ 9일차 까지
data_x = np.array(data_x)
data_y = np.array(data_y)
x_train, x_test, y_train, y_test = train_test_split(data_x, data_y, test_size=0.2)
model = keras.Sequential()
model.add(keras.layers.SimpleRNN(10, activation='relu', input_shape=(10,5)))
model.add(keras.layers.Dropout(0,1))
model.add(keras.layers.Dense(1, activation= 'sigmoid'))
stop = keras.callbacks.EarlyStopping(patience=10, restore_best_weights=True)
model.compile(loss= 'binary_crossentropy', optimizer='adam', metrics = 'accuracy')
model.fit(x_train, y_train,
validation_data = (x_test, y_test),
epochs=1000,
callbacks=[stop])
model.evaluate(x_test, y_test)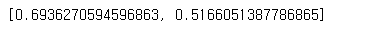
51.6% 로 획기적인 개선은 없다. 데이터량이 않을 수록 성능개선의 효과가 있다고 한다. 삼성전자 말고 다양한 주식데이터 SimpleRNN (단기기억) 보다 LSTM (장기기억)이 좀더 좋다고 한다.
data_x = []
data_y = []
window = 10
mean = np.mean(x, axis=0)
std = np.std(x, axis=0)
x = (x - mean)/std
for i in range(len(y)-window):
if y[i+window-1] < y[i+window]:
data_y.append(1)
else:
data_y.append(0)
data_x.append(x[i:i+window]) #0 ~ 9일차 까지
data_x = np.array(data_x)
data_y = np.array(data_y)
x_train, x_test, y_train, y_test = train_test_split(data_x, data_y, test_size=0.2)
model = keras.Sequential()
model.add(keras.layers.LSTM(10, activation='relu', input_shape=(10,5)))
model.add(keras.layers.Dropout(0,1))
model.add(keras.layers.Dense(1, activation= 'sigmoid'))
stop = keras.callbacks.EarlyStopping(patience=10, restore_best_weights=True)
model.compile(loss= 'binary_crossentropy', optimizer='adam', metrics = 'accuracy')
model.fit(x_train, y_train,
validation_data = (x_test, y_test),
epochs=1000,
callbacks=[stop])model.evaluate(x_test, y_test)
51.4% 로 획기적인 개선은 없다. 삼성전자 말고, 다른 주가 데이터 등 SimpleRNN보다 LSTM을 이용하면 좀더 좋은 결과를 얻을수 있을거 같다라는게 강의 결론이다. (강사왈)
다른 방법으로 추가 학습이 더 필요할 거 같다.
아무튼 예전보다 조금은 처음보다 익숙해 진듯. 더 나아 지겠지~~~
반응형
'백엔드 프레임워크 & 언어 > Python' 카테고리의 다른 글
| Selenium - find_element_by_css_selector는 대체 (0) | 2023.07.12 |
|---|---|
| Selenium을 활용한 웹 브라우저 테스트 자동화 (0) | 2023.07.12 |
| [프로젝트]데이터분석-머신러닝을 통한 삼성전자 주가 예측(10) (0) | 2023.07.10 |
| [프로젝트]데이터분석-머신러닝을 통한 삼성전자 주가 예측(9) (0) | 2023.07.10 |
| [프로젝트]데이터수집-머신러닝을 통한 삼성전자 주가 예측(8) (0) | 2023.07.09 |