프로젝트 형식으로 공부하면서 정리 하기
목표
1. 크롤링을 통해 네이버 금융주가 주가 가져오기
2. 머신러닝알고리즘을 적용해 주가 예측 모델 만들기
3. 성능 좋은 모델을 만들기
1-7. 표 데이터를 Pandas로 가져오기
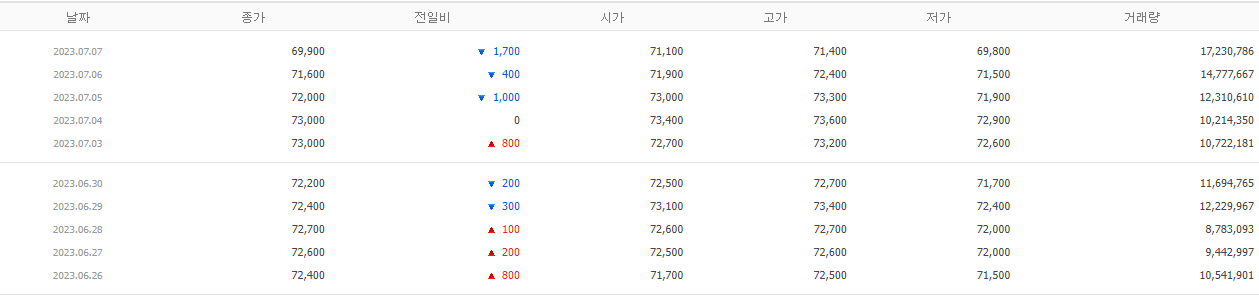
사실 해당 페이지에서 필요한 부분은 아래의 테이블 구조만 필요하다. 따라서 Dom 검색을 통해 해당 테이블만 추출하여야 한다.
페이지에서 마우스 오른 쪽 클릭 -> "검사"를 클릭해서 해당 DOM 구조를 찾는다.
Dom 중에 table Tag에 class가 속성값이 "type2" 임이 확인된다.

해당 Dom 구조 데이터만 가져오기
import requests # HTTP 요청 라이브러리
from bs4 import BeautifulSoup # python으로 HTML을 다루는 기능
import time #시간
import pandas as pd # 엑셀화
headers = {'User-Agent' : 'Mozilla/5.0 (Macintosh: Intel OS X 10_13_6}'}
url = " https://finance.naver.com/item/sise_day.naver?code=005930&page=1 "
url = requests.get(url, headers = headers)
html = BeautifulSoup(url.text) # 이 HTML처럼 보이는 Text를 진짜 HTML로 변환하기
html = html.find('table', class_='type2')
html
테이블 데이터 만 가져온게 확인된다.
반응형
'백엔드 프레임워크 & 언어 > Python' 카테고리의 다른 글
| [프로젝트]데이터수집-머신러닝을 통한 삼성전자 주가 예측(8) (0) | 2023.07.09 |
|---|---|
| [프로젝트]데이터수집-머신러닝을 통한 삼성전자 주가 예측(7) (0) | 2023.07.09 |
| [프로젝트]데이터수집-머신러닝을 통한 삼성전자 주가 예측(5) (0) | 2023.07.09 |
| [프로젝트]데이터수집-머신러닝을 통한 삼성전자 주가 예측(4) (0) | 2023.07.09 |
| [프로젝트]데이터수집-머신러닝을 통한 삼성전자 주가 예측(3) (0) | 2023.07.09 |