목표
1. 크롤링을 통해 네이버 금융주가 주가 가져오기
2. 머신러닝알고리즘을 적용해 주가 예측 모델 만들기
3. 성능 좋은 모델을 만들기
1-7. 페이징처리된 모든 데이터 가져오기
우리는 기존에 1페이지에 해당하는 데이터만 가져왔다. 근데 가져올 데이터는 아래와 같이 전체 679 페이징 데이터가 모두 필요하다.

1) for 문을 돌려서 679 페이지 까지 데이터를 가져오기 위해 range(1,680)
2) 모든 데이터를 취합하기 위한 total list 생성
3) for문의 시간을 측정하기 위해 tqdm 라이브러리 임포트 및 설정
4) 크롤링한 데이터를 저장하기 위해 total.append(table)
5) 크롤링시 서비스에 문제없고, DoS로 오해받지 않도록 sleep(1) 설정
import requests # HTTP 요청 라이브러리
from bs4 import BeautifulSoup # python으로 HTML을 다루는 기능
import time #시간
import pandas as pd # 엑셀화
from tqdm import tqdm # for문의 진행상황을 확인할수 있는 라이브러리
headers = {'User-Agent' : 'Mozilla/5.0 (Macintosh: Intel OS X 10_13_6}'}
total = []
for n in tqdm(range(1,680)):
url = "https://finance.naver.com/item/sise_day.naver?code=005930&page={}".format(n)
url = requests.get(url, headers = headers)
html = BeautifulSoup(url.text) # 이 HTML처럼 보이는 Text를 진짜 HTML로 변환하기
html = html.find('table', class_='type2')
table = pd.read_html(str(html))[0]
table = table.dropna()
total.append(table)
time.sleep(1)크롤링하는 진도를 볼수 있다. (tqdm 모듈 사용)


20여분 정도걸려서 크롤링완료!
첫페이지의 데이터를 살펴보자
total[0]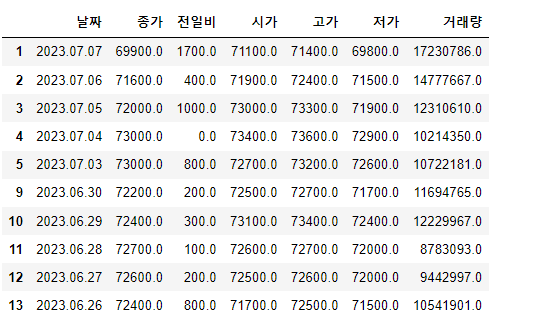
두번째 페이지의 데이터를 살펴보자
total[1]
len 함수를 이용하여 전체 몇개의 표가 들어 있는지 보자!
len(total)
679개의 표가 들어 있는데 데이터처리를 용이하게 하기 위해서 하나로 합치자!
pd.concat(total)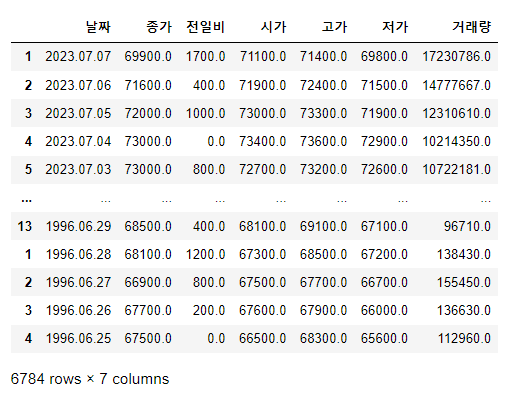
그런데 그냥 붙였더니 인덱스 값이 불규칙하다. ignore_index=True를 넣어 index를 정렬하자
samsung = pd.concat(total, ignore_index=True)
samsung
우리는 과거데이터에서 미래 데이터를 예측해야 하기 때문에 날짜를 역순으로 정렬하자
samsung = samsung[::-1] # 처음부터 끝열까지 -1, 역순으로 정렬
samsung

excel로 데이터를 저장하기
samsung.to_excel('samsung.xlsx')저장된 파일을 확인하자. 다음을 위해~
반응형
'백엔드 프레임워크 & 언어 > Python' 카테고리의 다른 글
| [프로젝트]데이터분석-머신러닝을 통한 삼성전자 주가 예측(10) (0) | 2023.07.10 |
|---|---|
| [프로젝트]데이터분석-머신러닝을 통한 삼성전자 주가 예측(9) (0) | 2023.07.10 |
| [프로젝트]데이터수집-머신러닝을 통한 삼성전자 주가 예측(7) (0) | 2023.07.09 |
| [프로젝트]데이터수집-머신러닝을 통한 삼성전자 주가 예측(6) (0) | 2023.07.09 |
| [프로젝트]데이터수집-머신러닝을 통한 삼성전자 주가 예측(5) (0) | 2023.07.09 |